Grafy máme a tak se podíváme co dál

Nějaký čas jsme vám nedali vědět, jak se nám daří. Poslední měsíc jsme pracovali primárně na monitoringu a grafech. S těmi jsme teď hotovi a v dubnu a květnu se nyní chceme zaměřit na zpětnou vazbu od administrace. Chceme ji rychlejší, odstranit synchronní provádění akcí, co mohou jít na pozadí a také by vám měla říct, kde je problém, když zrovna něco nefunguje.
Pokud jste byli poslední dobou v naší administraci, asi jste si všimli, že jsme do karty s grafy přidali slíbená chybějící data, která jsme k aplikacím měly, ale využívali jsme je jen při hledání problému. Teď máte možnost tato data prohlížet taky.
Díky této změně jsme se kompletně zbavili InfluxDB a celé Roští už teď jede na Prometheu. O jednotlivých aktualizacích jsme informovali různě na Twitteru.
Přepisujeme grafy, abychom se zbavili InfluxDB a protože o vašich aplikacích sbíráme víc provozních dat, než jsme doposud ukazovali, tak tuto chybu napravujeme. Tuhle novinku si budete moct vyzkoušet možná už tento týden. pic.twitter.com/MTYNnkL4w7
— Roští.cz (@rosti_cz) March 18, 2021
Důvod, proč jsme zahodili InfluxDB je především jednoduchost a rychlost s jakou v našem případě Prometheus funguje. Téměř bez ladění nám dává stabilní výsledky bez ohledu na množství dat. Navíc na serveru využívá méně paměti. Z druhé strany se z něj zase snadněji dostávají data a ani k tomu není potřeba další závislost v administraci, ale vystačíme si s klasickým requests.
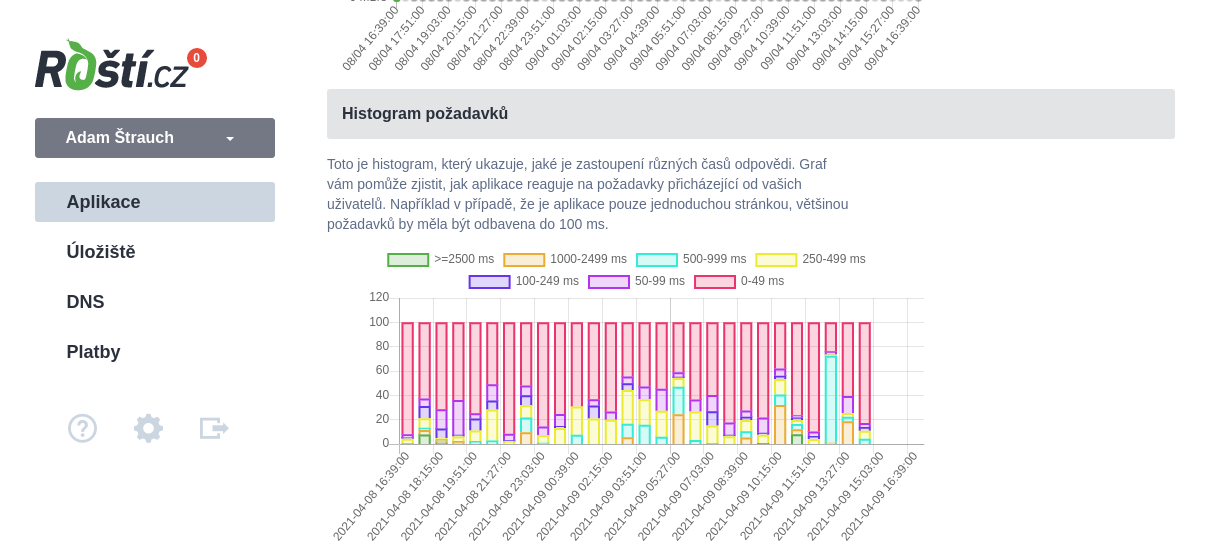
V grafech nyní najdete kromě využití paměti a procesoru také využití disku a množství IO operací. Aktivitu sítě a HTTP provozu. Zajímavý pro někoho může být histogram času odezvy, díky kterému lze zjistit, jak rychle vaše aplikace odpovídá na požadavky a mimo jiné tam najdete i statistiky HTTP status kódů, což vám pomůže zjistit, jestli vaše aplikace negeneruje moc chybových odpovědí a tím třeba odhalit nějak skrytý problém.
Chceme se teď zaměřit na sledování stavu aplikace
S monitoringem obecně máme ještě nějaké plány. Chtěli bychom vylepšit rozhraní, aby bylo více podobné Grafaně a bylo by dobré do administrace dostat i logy. To jsou ale vzdálenější plány, protože teď se chceme zaměřit na zobrazení stavu aplikace a infrastruktury s ní spojené.
Našim cílem je zobrazit v info kartě aplikace něco takového:
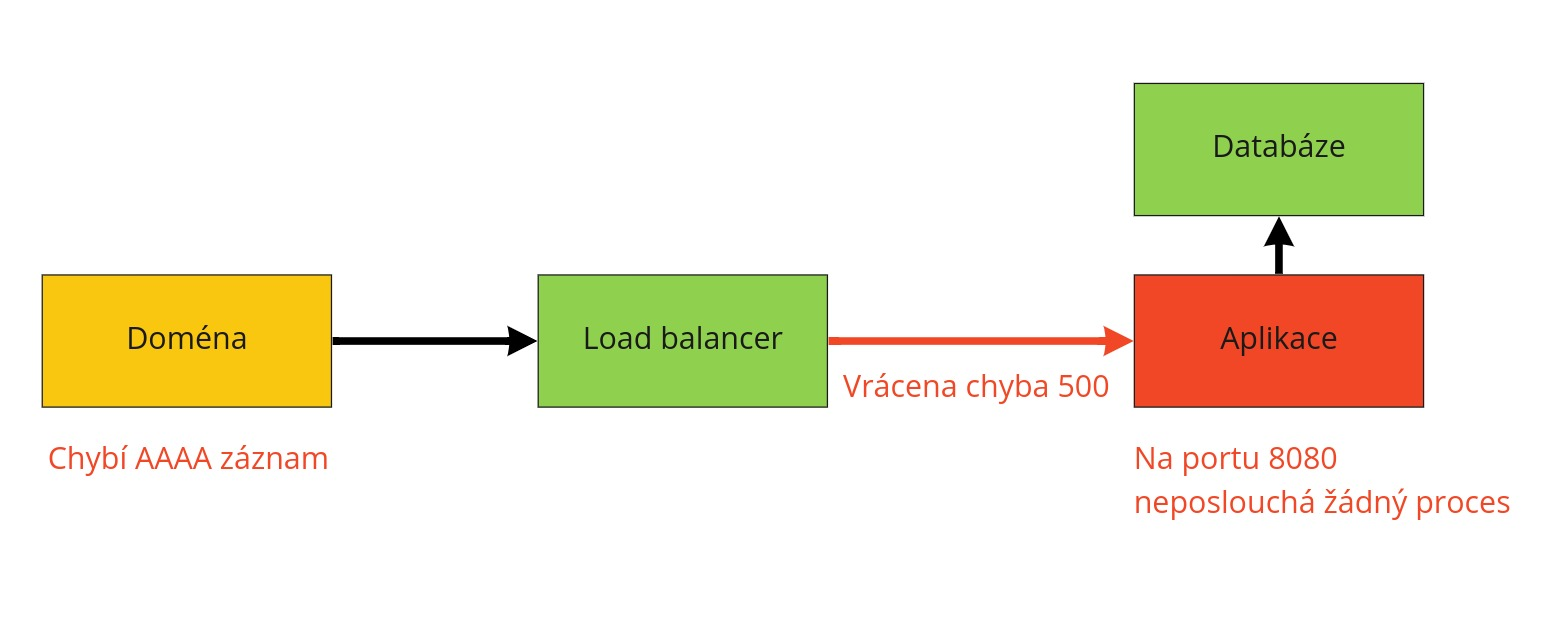
Diagram, který znázorňuje schéma infrastruktury a pokud naše systémy někde narazí na problém, tak ho zobrazí v místě, kde k němu došlo. U chybové hlášky bude také malé vysvětlení o co jde a co s tím dělat. Mělo by to pomoct hlavně začátečníkům, ale i pokud už naše prostředí znáte, tak vám to pomůže odhalit problémy rychleji.
Některá data a nástroje na jejich získání už máme, takže bude stačit vytvořit k nim rozhraní. V současné době ale nemáme nic, co by měřilo stav databáze, kromě jednoduchých skriptů. Stejně na tom je vnitřek aplikace, kde bychom rádi monitorovali více věcí. Do diagramu zapojíme i náš monitoring, takže pokud bude problém v naší infrastruktuře, budete vědět čeho přesně se týká.
Zpětná vazba od administrace
Po změnách minulý rok je naše administrace blesková, zvlášť když u nás máte jen pár aplikací. Jsou ale stránky, které se načítají déle a pokud třeba mažete aplikaci, tak tyto akce probíhají synchronně. V době, kdy jsme to psali, to bylo nejjednodušší řešení, protože jsme nemuseli řešit stavy, kdy se vytváří aplikace a než ten proces doběhne, tak mohla být odstraněna.
Aktuálně tedy migrujeme na Django 3 a chceme začít více těžit z asynchronního provádění změn v infrastruktuře. Až budeme hotovi, tak když pak vytvoříte novou aplikaci, dostanete okamžitě odpověď od administrace, že to je v procesu a také informaci o tom, že je vše hotovo. Stejná změna se ale týká výpisu aplikací. Teď se totiž kontaktují všechny servery, na kterých vaše aplikace běží, aby o nich administrace získala informace. Ty ale mohou být uloženy v lokální databázi a v případě, že na serveru dojde ke změně, informuje o tom server administraci sám.
Kromě aktualizace Djanga jsme si tedy zprovoznili NATS server pro výměnu zpráv mezi službami. Chtěli jsme původně použít Redis, ale NATS je přeci jen o kousek dál. Dokáže zprostředkovat přijetí zprávy nebo zařídil balancování zpráv mezi přihlášené odběratele a protože nemá žádné úložiště, tak se lépe škáluje. Umí dokonce koncept request-response, takže dokáže zprostředkovat třeba přístup do databáze skrze microservice k tomu určenou.
První části administrace, která pojede přes NATS bude správa databází. Ta je teď pevnou součástí administrace, ale chceme ji, stejně jako správu aplikací, DNS a load balanceru, přesunout mimo a administraci dát k dispozici jen API, resp. NATS. V této části se nám otevírá možnost, kterou jsme chtěli mít na Roští už před lety a to přidání možnosti běhu custom databáze. Tedy databáze, která by byla jen pro vás, měli byste do ní root přístup a možnost změnit cokoli v její konfiguraci. Pravděpodobně si k tomu necháme minimálně otevřená vrátka.
Pro dnešek to je všechno. Pokud máte nějakou otázku nebo návrh na zlepšení, jsme tu pro vás na chatu i na Twitteru. Klidně nám napište i jen to, že se vám služba líbí, i to nás potěší :-)