Architektura chytrého hostingu

V posledních několika týdnech řešíme změny šifrování v naší infrastruktuře a řekli jsme si, že to je příležitost, jak vám ukázat, jak Roští pod pokličkou funguje. Nepoužíváme žádnou raketovou technologii, ale děláme věci jinak než ostatní. Nemáme vlastní servery, ale běžíme převážně v cloudu. To na jednu stranu přináší náklady navíc, na druhou se můžeme soustředit na to co umíme dobře. Cloud je ale široký pojem a my jsme si v něm museli najít cestu. Nebylo to ze dne na den a ne vše je perfektní.
Roští infrastruktura
Pokud u nás provozujete nějakou produkční aplikaci, mohou vám následující řádky osvětlit, jakou roli v Roští vaše aplikace zastává. Bude vás určitě zajímat kombinace služeb, kterou používáme nebo cesta, kterou tečou vaše data. Pojďme se mrknout na schéma našeho produkčního prostředí:
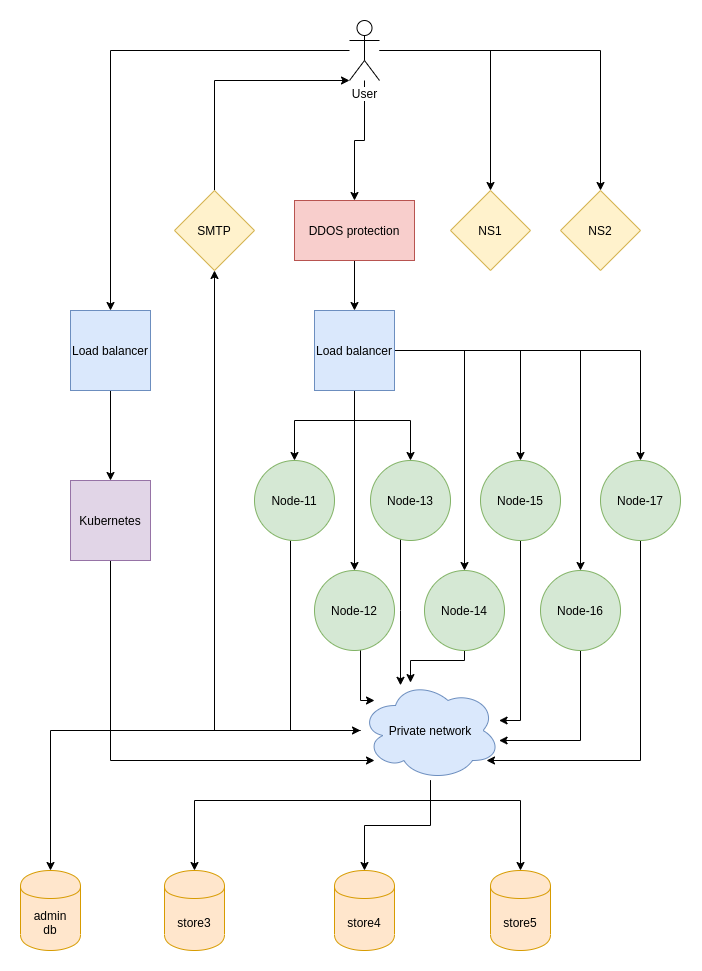
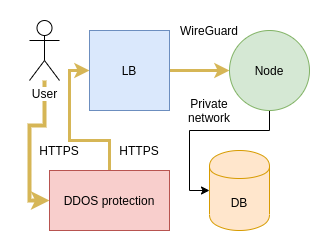
Vstupním bodem je uživatel, což může být buď uživatel navštěvující vaše aplikace a nebo uživatel, který mění něco v administraci. V případě, že uživatel přistupuje na vaši aplikaci, jde požadavek do Brna na load balancer hostovaný v cloudu Master.cz. Před load balancerem je nainstalovaná DDOS ochrana, která nám mnohokrát pomohla, ale už se jí povedlo na několik minut sestřelit i spojení k jednomu z nodů. Tento load balancer provozujeme už čtvrtým rokem a se samotným serverem jsme za tu dobu řešili jediný problém a to náhodné výpadky sítě. Master Cloud tedy můžeme jen doporučit.
Na load balanceru se nachází šifrované tunely. Jeden ke každému z nodů. Nově na šifrování používáme Wireguard, který se nedávno dostal do linuxového jádra. Asi dva měsíce jsme ho testovali na jednom z nodů a nedávno ho nasadili na všechny. Mezi uživatelem a load balancerem pak funguje HTTPS - pokud si ho v administraci zapnete.

Když požadavek dorazí na node, většina procesování se odehrává na něm. Výjimkou jsou databáze, které jsou na oddělených serverech a přistupuje se k nim po neveřejné síti. Databáze nejsou dostupné jinak než z nodů, takže pokud k nim chcete přistupovat z lokálního počítače, musíte k tomu použít SSH tunel.
Důvodů pro oddělení load balanceru od nodů je hned několik. Je docela složité sehnat DDOS ochranu za rozumnou cenu a Master nám zde vyšel maximálně vstříc. Druhý důvod je právní. Pokud přijde požadavek na odstranění nějakého obsahu, tak nemáme úplně důvěru v DigitalOcean, že nám neodstřihnou celý node nebo dokonce celý účet. U Masteru už jsme tuto situaci řešili a vyřešili způsobem, kde byly spokojené všechny strany včetně majitele postiženého webu. Pokud už by došlo na nejhorší, můžeme s load balancerem cestovat různě po internetu a oddělit postiženou aplikaci od aplikací, kterých se problém netýká.
Load balancer už pamatuje naše fyzické servery, pokusy ve ScaleWay i současné nody v DigitalOcean a během stěhování jsme díky němu nemuseli měnit IP adresu vstupního bodu do naší infrastruktury. Nad velkou částí domén nemáme žádnou kontrolu, tak je pro nás důležité mít tyto IP adresy u někoho, komu věříme.
Všechny současné nody provozujeme na Frankfurtských serverech od DigitalOcean. Původně jsme začínali v Coolhousingu s jedním serverem, kterému jsme později pořídili ještě jeden další. Pak jsme se přestěhovali do Masteru a skončili na šesti serverech. Vlastnit fyzické servery pro nás ale nebylo úplně nejlepší. Stávaly se různé nehody jako špatný napájecí kabel, kvůli kterému se server vypnul když se kolem něj někdo pohyboval, dvakrát došlo k výpadku proudu na jedné i obou větvích napájení a samozřejmě občas chtěly servery více paměti nebo vyměnit disky. V té době jsme byli dva a i tak bylo složité kamkoli odjet, protože problémy přicházely náhodně. Chtěli jsme proto do cloudu.
První volbou pro nás bylo Scaleway, kde jsme bohužel naráželi na velké problémy se stabilitou serverů a dokonce jsme jednou přišli o celý stroj a museli ho obnovovat ze zálohy. Skutečným problémem Scaleway je ale podpora, kde většinu času je jen člověk, který tickety předává dál a jejich vyřešení může trvat i dny až týdny. Naposledy jsme Scaleway zkoušeli před dvěma měsíci, kdy jsme chtěli využít jeden z jejich store serverů na zálohování. Bohužel byla jejich webová utilita na dělení disku rozbitá a instalace serveru vždy skončila nefunkčním strojem. Podpora nám po pár zprávách odepsala, že si máme na instalaci někoho najmou, když to neumíme sami. Svérázná podpora je jedna věc, ale jinak Scaleway roste a i když jim to trvá, z chyb se nakonec poučují. Scaleway tedy zase zkusíme za dalších pár let, možná se už dostanou tam kam potřebujeme.
U nodů jsme v poslední době přešli na stroje s 8 GB RAM, kam se vejde v průměru kolem 50 aplikací. Aktivní node vybíráme ručně na základě monitoringu. Máme různé balíčky pro aplikace s různými potřebami, takže některé nody zvládají třeba 2-3 aplikace, jiné jich mají 60. Nody 11 až 14 jsou větší. Mají 16 GB RAM a v průměru odhostují 100 aplikací. S aplikacemi na nodech se snažíme nehýbat. Děláme to jen v případě, kdy si nějaký uživatel zaplatí vyšší balíček a začne node nepoměrně vytěžovat. V takovém případe jde na jiný stroj a dostane vyhrazenou paměť čistě pro sebe. Většina hostovaných aplikací takový luxus ale nepotřebuje, protože buď nevyužijí paměť, kterou jsou omezeny a nebo ji potřebují jen někdy.
V cloudu je paměť drahá, alespoň pro náš hosting, kde se snažíme držet cenu na částce dostupné komukoli a s přechodem na cloud jsme se dostali na hranu toho co je při naší velikosti možné. Kdybychom zůstali u fyzických serverů, pravděpodobně bychom dnes měli lepší parametry i se stávající cenou, než máme teď. Na druhou stranu paměť není všechno a je pro nás důležitější mít možnost opravit problém odkudkoli než přidat na balíčku pár MB RAM navíc.
Každý náš server, ať to je node, SMTP server, databáze nebo DNS server pečlivě sledujeme pomocí kombinace Telegraf, InfluxDB a Grafana. Máme přehled o využití jednotlivých nodů a také jakým způsobem zatěžují nody jednotlivé aplikace. Jsme tedy schopni rychle zjistit kde je problém, pokud se začne dít něco nestandardního.
Všechny naše servery jsou konfigurovány přes Ansible. Server jako takový přidáváme ručně, ale jejich instalace už je v režii Ansiblu. Nový node nebo nová databáze jsou většinou otázka 15 minut až půl hodiny. Ansiblem je spravovaný i load balancer.
Kde bydlí administrace
Administrace a další podpůrné služby běží v Kubernetes clusteru od DigitalOcean. Ten je taktéž umístěn ve Frankfurtu a využívá databázi mimo tento cluster. V Kubernetes nám běží:
- Administrace,
- Grafana,
- InfluxDB.
- phpMyAdmin,
- Adminer,
- Sentry.
Cluster má svůj vlastní load balancer od DigitalOcean. Zajímavostí je, že když jsme všechny služby přesunuly do Kubernetes, skončili jsme s účtem třikrát vyšším, než stál původní server, kde toto všechno běželo také. Zpátky se ale vracet nebudeme.
Kubernetes cluster má smysl tam, kde je potřeba zajistit vyšší dostupnost a škálovatelnost. V prvním případě má ale cluster od DigitalOcean mezery, protože nepodporuje nody běžící v různých regionech. Dá se ale výborně škálovat a volíme ho v případě, kdy se nějaký zákazník chce posunout z našeho standardního hostingu o level výš.
I když administrace nemá žádné špičky v návštěvnosti a během dne ji navštíví jen několik lidí, jejím dlouhodobým umístěním v Kubernetes jsme se naučili ledasco zajímavého. Nedávno jsme třeba zjistili, že master server od DigitalOcean, ke kterému nemáme jako zákazníci DigitalOcean přístup, nemá moc paměti a pokud ho provozujete dost dlouho a paměť se naplní, začne se celý cluster chovat vrtošivě. Dochází k náhodným pádům podů a z logů není úplně jasné proč. Naštěstí na náš popud podpora velmi rychle zareagovala a problém vyřešila.
Cena Kubernetes clusteru je marginální proti změnám, které je potřeba udělat v kódu aby mohl těžit z výhod běhu v clusteru. Aplikaci je potřeba rozdělit na části, které běží stateless a části, které ukládají nějaká data. Ta většinou končí v nějaké databázi, což je i náš případ. Administraci jsme tedy museli nacpat do Docker image a připravit automatizovaný proces pro build, testování a deploy. Chvíli jsme na to používali Concourse. Je to vynikající nástroj, ale vyžaduje pozornost, která je mimo naše možnosti. Jak na zavolanou tedy přišel GitHub se svými Actions a od listopadu minulého roku používáme jen to.
GitHub nedávno slevil na balíčcích pro teamy, které jsou nově zdarma a za trochu lepší podmínky se platí $4 za uživatele měsíčně. Actions můžete používat i v kombinaci s naším hostingem na Roští.
Zálohování
Kromě load balanceru, nodů a databází se mohou vaše data objevit ještě na serverech pro zálohování. Aktuálně používáme Backblaze a všechny naše servery jsou jednou denně zkopírovány na jejich servery, kde držíme historii několika dní. To samé platí pro databáze, jen historie je 30 dní. O zálohování NS serverů se stará DigitalOcean a zálohují se celé stroje. Podobně to máme se SMTP serverem, kde se konfigurace mění sotva dvakrát ročně a tak jednoduše zálohujeme celý stroj.
Zálohování nodů nám v současné době úplně nevyhovuje. Problém je, že musíme každou noc posílat přes 600 GB dat na servery Backblaze, což nás stojí hodně odchozího trafiku a především trvá zálohování tak dlouho, že nemůžeme zálohovat víc než jednou denně.
Jeden čas jsme měli nasazený Restic, který nám maximálně vyhovoval z uživatelského pohledu. Bohužel generujeme spoustu malých souborů a u některých našich nodů vyžaduje až 5 GB RAM během zálohování. To je bohužel nad možnosti našich nodů. Nezanevřeli jsme ale na něj. Existuje pull request, který problém řeší, jen nebyl zanesený do hlavní větve.
Máme i řadu plánů
Naše infrastruktura prochází malými změnami každou chvíli. O většině těchto pokusů se nerozepisujeme, protože se do produkce nedostaly. Ale rádi bychom to změnili. I nepodařené pokusy mohou být zajímavé.
Aktuálně se teď plánujeme pustit do následujících oblastí:
- Fyzický server pro zálohy,
- uzavření node serverů (pouze SSH),
- zrušení FTP protokolu,
- vlastní vrstva mezi Dockerem a administrací,
- nody na Vultr,
- Traefic nad loadbalanceru.
Rádi bychom co nejdříve nasadili zálohování pomocí rsync, btrfs a jeho snapshotů. Nemuseli bychom tak přenášet všechna data, ale pouze změny a verzovat přes snapshoty. Máme s tímto způsobem zálohování zkušenosti a funguje výborně. Problém je, že se v tomto případě nevyhneme fyzickému stroji umístěnému v některém z datacenter. Je to jeden z limitů cloudových služeb, které s takovým procesem nepočítají. U záloh to ale zas tolik nevadí. Projekt máme rozjetý a brzy o něm napíšeme více.
Aktuálně jsou HTTP porty na nodech otevřeny do internetu. Komunikace mezi load balancerem a nody je šifrovaná, ale přímý přístup na node nebude ani při zapnutém HTTPS. To totiž řeší až load balancer. Proto bychom rádi schovali nody čistě do privátní sítě a vytvořili malý server, který by pracoval jako TCP proxy server pro SSH spojení k jednotlivým kontejnerům. Abychom tohoto dosáhli, musíme se zbavit FTP, které by v takovém režimu nemohlo fungovat. Díky této změně bychom mohli migrovat aplikace ze serveru na server, aniž byste museli cokoli měnit ve vašich deploy skriptech, protože SSH server by se neměnil bez ohledu na to, kde aplikace běží.
U NS serverů jsme se rozhodli jít cestou malé služby, která běží na jednom z těchto strojů a stará se o veškerou práci s DNS. Administrace pak používá jednoduché API, aby mohla DNS záznamy přidávat, mazat a měnit, ale všechno ostatní je v režii těchto serverů. Pro vývoj se tento způsob ukázal k nezaplacení, protože REST API se mockuje přeci jen o něco lépe než SSH spojení a chtěli bychom to samé využít na nodech.
Stejný postup bychom rádi implementovali do nodů. Na každém nodu by běžela malá služba, která by nabízela administraci REST API pro práci s kontejnery na daném serveru. Zároveň by se tato služba starala o pár detailů. Řešíme už pár let problém, že když kontejneru dojde paměť a OOM killer odstřelí jeden z jeho procesů, víme že se to stalo, ale nevíme komu. S touto službou bychom mohli OOM killer hlídat a porovnávat s tím, co jsme sesbírali za data z jednotlivých kontejnerů.
Jedním z objevů minulý rok pro nás byla DDOS ochrana u Vultru. Přemýšlíme tedy jak otestovat pár desítek webů, aniž bychom nějak komplikovali administraci. Aplikace totiž musí běžet co nejblíže databázi a chceme se vyhnout situaci, kdy si musíte vybrat, v jaké lokalitě chcete databázi mít. Důvodem pro DDOS ochranu od Vultr je především záloha, kdyby se s naším současným řešením něco stalo. Limitujícím faktorem je drahý odchozí trafik. Pokud bychom tam neměli žádné nody, bylo by to velmi drahé.
Co nás poslední dobou pálí čím dál víc je nestabilita Nginxu na load balanceru. Náhodné pády spojení, procesy co zůstávají viset po reloadu konfigurace, neschopnost načíst novou konfiguraci na části workerů, to jsou všechno věci, se kterými jsme posledních 6 měsíců bojovali a tak si začínáme říkat, zda by nestálo za to zkusit nějakou alternativu, třeba Traefic. Chtěli bychom do administrace přidat statistiku požadavků, které jdou na aplikaci a Traefic by nám tu mohl pomoci. Nginx to bez externích pluginů nedokáže, tak jak bychom chtěli.
Pár slov na závěr
Vážíme si, že jste dočetli až sem. Snažili jsme se text zkrátit, ale nakonec to moc nešlo. Pokud se vám líbí co děláme a ještě u nás nemáte hosting, tak budeme moc rádi, když to s námi zkusíte. Pokud u nás hosting máte, tak vám moc děkujeme za důvěru, kterou do nás vkládáte.
I když jsou informace sepsané výše velmi důležité v případě, že u nás máte třeba váš business, doposud jsme je nikde takto souhrnně nepublikovali. Tímto to tedy napravujeme a nějakou zkrácenou formu připravíme ještě do dokumentace, kam toto určitě patří.