Výpadek 27.8.2024


V úterý 27.8. nás potkal výpadek služeb, který trval necelé 4 hodiny. Bolestnější je to pro nás o to víc, že nebyl na naší straně a neměli jsme tak v rukou jeho řešení. Pojďme si projít, co se vlastně stalo.
V 10:09 došlo k výpadku většiny aplikací, resp. všech, které mají domény nasměrované na lb.rosti.cz, náš load balancer (LB). Jedná se o malý cloudový server hostovaný v Master Cloudu. Důvody, proč to takto máme, jsou historické. Umožňuje nám to stěhovat infrastrukturu mezi cloudovými službami i datacentry s minimálními dopady na dostupnost.
LB má vytvořené šifrované tunely na tři fyzické servery v datacentru taktéž u Masteru. Pouze jeden z šifrovaných tunelů je aktivní pro komunikaci s aplikacemi. Ostatní jsou záložní.
K výpadku služeb došlo v 10:09.
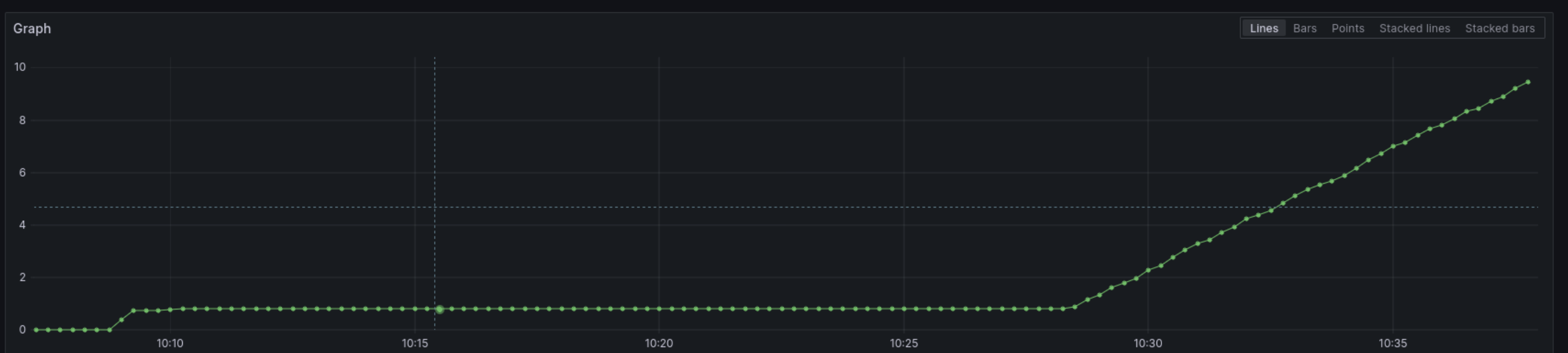
V té době vypadl jeden z šifrovaných tunelů. Problém jsme začali řešit po devíti minutách, přibližně v 10:18. Nebylo hned jasné, co se děje, ale po chvilce jsme zjistili, že LB nemá spojení k aplikacím a v 10:28 jsme přepnuli na jiný tunel, který fungoval.
Poté se aplikace rozjely, ale zároveň spojení nebylo stabilní a aplikace náhodně vypadávaly.
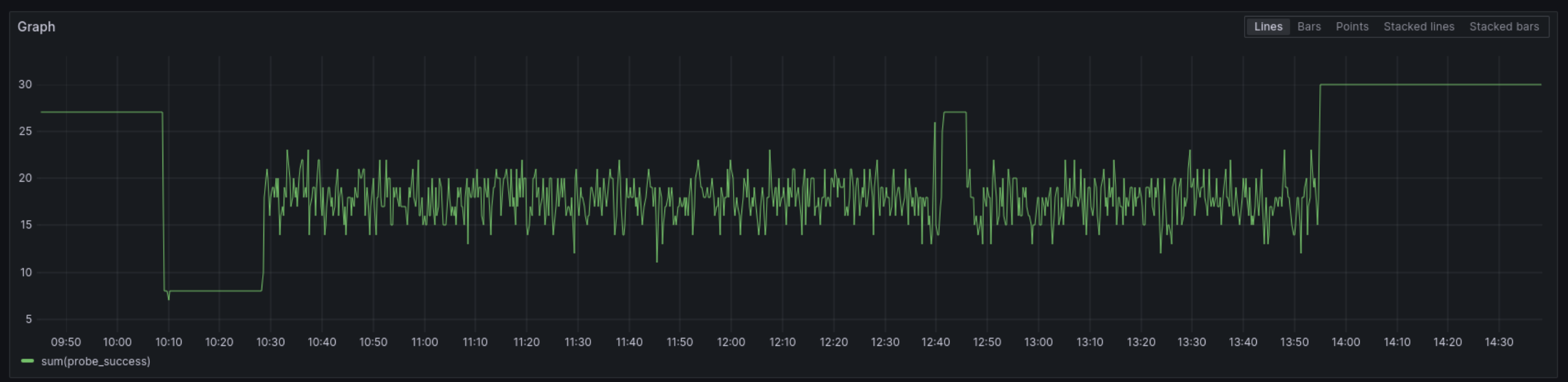
Na grafu je vidět, že jsme měli 27 monitorovaných aplikací a po přepnutí tunelu nebyl jediný moment, kdy by byly všechny online. Problém nedával smysl, protože jedna aplikace fungovala a druhá ne, i když používaly stejný tunel. Zároveň pingy procházely a na LB jsme měli otevřené stabilní SSH spojení.
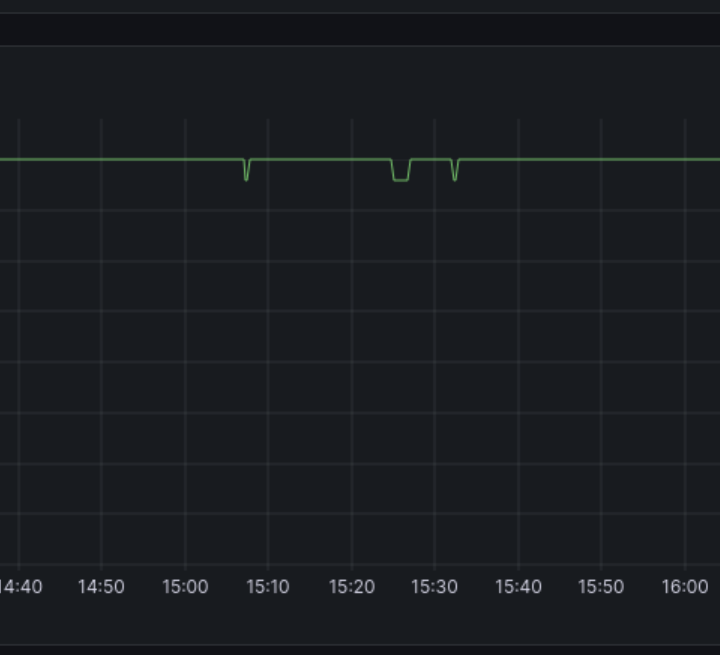
Kolem 11:20 jsme si všimli, že z naší kanceláře se ping na LB choval takto:

A pojali jsme podezření, že se něco děje v síti Master DC. V 11:28 jsme kontaktovali podporu. Ve 12:08 jsme dostali zprávu, že problém analyzují. Podle grafu výše bylo vidět, že aplikace začaly na několik minut fungovat kolem 12:40, ale k obnovení provozu došlo až ve 13:55.
V tento moment jsme dostali následující oficiální vyjádření od Masteru:
Jedná se s největší pravděpodobností o problém v software switche, který obsluhuje část infrastruktury, kde je umístěn váš server. Emergency reload proběhne od 15:00 CEST.
V 15:07, 15:25 a 15:32 došlo k několika krátkým výpadkům a od té doby jsme považovaly problém za vyřešený.
Po diskusi s lidmi z Master DC víme, že po desáté hodině došlo na jejich straně k vyčistění ARP tabulek, což vedlo ve switchích ke stavu, kdy přestaly správně pracovat. Informace o problému předali jejich dodavateli a budou to s ním dál řešit.
Z naší strany jsme se snažili najít způsob, jak se tomuto problému příště vyhnout. Nakonec jsme zvolili řešení rozdělit LB na dva servery ve dvou lokalitách a dát jim sdílenou anycastovou IP adresu. Problémový stroj pak můžeme snadno odříznout.
Bohužel změna bude vyžadovat zásah na všech stranách. Master nám připraví routování skrze BGP protokol, my musíme upravit službu, která spravuje LB, aby byla schopná fungovat na dvou a více serverech a na straně našich uživatelů bude potřeba změnit IP adresu současného LB za novou anycastovou.
Implementace ještě chvíli potrvá a budeme vás postupně informovat o postupu.
Na závěr se chceme omluvit za komplikace, které tato situace způsobila. Snažíme se z ní maximálně poučit, aby se už neopakovala.